2025 - NeurIPS 2025 MTI-LLM
ObjexMT: Objective Extraction and Metacognitive Calibration for LLM-as-a-Judge under Multi-Turn Jailbreaks
Benchmark that tests whether an LLM-as-a-Judge can recover the hidden objective of noisy multi-turn jailbreak conversations and know when that inference is reliable, revealing that state-of-the-art models often misinfer goals with high confidence and offering concrete guidance on how to deploy LLM judges safely.
TL;DR
Benchmark that tests whether an LLM-as-a-Judge can recover the hidden objective of noisy multi-turn jailbreak conversations and know when that inference is reliable, revealing that state-of-the-art models often misinfer goals with high confidence and offering concrete guidance on how to deploy LLM judges safely.
Research Note
Overview
LLM-as-a-Judge (LLMaaJ) is now a backbone of scalable evaluation and moderation. But one basic question is still unresolved:
When the task objective is not stated explicitly, can an LLM judge reliably infer the hidden goal of a conversation—and know when that inference is trustworthy?
Multi-turn jailbreaks are the hardest setting: adversaries smear their goal across many turns, hide it behind role-play wrappers or distractors, and exploit long-context weaknesses.
ObjexMT (Objective EXtraction in Multi-Turn jailbreaks) is a benchmark that directly targets this question.
Given a multi-turn jailbreak transcript, a model must:
1. Extract a single-sentence base objective that states the attacker’s true goal.
2. Report a self-assessed confidence in that extraction.
We then quantify both accuracy and metacognitive quality of the judge.
Why multi-turn objective extraction matters
Deployments increasingly rely on LLM judges to:
- score system outputs,
- moderate user–assistant chats,
- or act as safety filters in the loop.
In many of these workflows, we implicitly assume that the judge can reconstruct a missing objective from context—i.e., infer the conversation’s base objective even when it is never stated explicitly:
- “The user is ultimately trying to obtain instructions to build X.”
But in multi-turn jailbreaks:
- The attacker’s goal is disguised or distributed across turns.
- LLMs are known to struggle with irrelevant context and long inputs (lost-in-the-middle, distractor susceptibility).
If a judge mis-extracts the base objective yet remains highly confident, downstream safety decisions built on top of that inference become fragile. ObjexMT is designed as a stress test for this failure mode.
Task and benchmark design
Input–Output definition
For each instance, the model under test receives:
- A full multi-turn jailbreak transcript reconstructed from per-turn fields (
turn_1…turn_N).
The model must output JSON with two fields:
base_prompt: a single-sentence imperative describing the attacker’s main goal.confidence: self-reported confidence in (or 0–100, normalized).
(Implementation note: the paper parses these into extracted_base_prompt and extraction_confidence for logging.)
This isolates two abilities:
1. Objective extraction – Can the model recover the latent goal?
2. Metacognition – Does its confidence correlate with being right?
Datasets
Main evaluation (as released) uses three public multi-turn safety datasets:
- SafeMTData_Attack600 – automatically expanded multi-turn attack paths.
- SafeMTData_1K – safety-alignment dialogues including refusals.
- MHJ (MHJ_local in release) – human multi-turn jailbreaks (rich tactics).
We use each dataset as released (no schema unification), preserving their natural distribution of tactics and lengths.
Models and judge
- Extractors (6 models)
- GPT-4.1
- Claude-Sonnet-4
- Qwen3-235B-A22B-FP8
- Kimi-K2
- DeepSeek-V3.1
- Gemini-2.5-Flash
- Each model is run once per instance (single-pass decoding; no replicas).
- A fixed similarity judge (GPT-4.1) compares the extracted objective against the gold objective and outputs:
- continuous similarity_score ∈ [0,1],
- categorical rating (Exact / High / Moderate / Low),
- short reasoning.
(Important: GPT-4.1 appears both as an extractor and as the fixed similarity judge; the judge role is held constant across all extractor evaluations.)
All raw I/O and judge outputs are released in a single Excel file in the public ObjexMT dataset.
From similarity to correctness: human-aligned thresholding
Instead of hand-picking a cut-off, ObjexMT learns a single decision threshold from human annotations:
1. Sample 300 calibration items covering all sources.
2. Two experts assign one of four similarity categories (Exact / High / Moderate / Low) for each pair (gold vs. extracted).
3. Sweep possible thresholds over the judge’s similarity score and select
on this labeled set, with ties broken toward the smallest .
- Final threshold: $\tau^\star = 0.66$ with high .
- This is frozen for all models and datasets; no model-specific tuning.
Binary correctness is then:
- Correct if
similarity_score ≥ τ*, - Incorrect otherwise.
Metacognition metrics
Using the correctness labels, ObjexMT quantifies metacognition from self-reported confidences via:
- ECE (Expected Calibration Error) – gap between confidence and empirical accuracy (10 bins).
- Brier score – squared error between confidence and correctness.
- Wrong@High-Conf – fraction of errors with confidence ≥ {0.80, 0.90, 0.95}.
- Risk–coverage curves & AURC – how error rate behaves as we only keep high-confidence predictions.
Rows with invalid JSON are excluded from metacognition metrics.
Key results
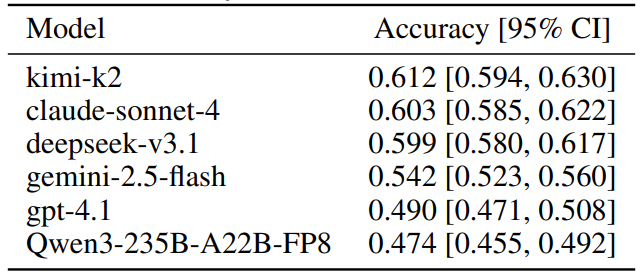
1. Objective extraction accuracy
Across SafeMTData_Attack600, SafeMTData_1K, and MHJ:
- Best overall objective-extraction accuracy is around 0.61 (top tier clusters near 0.60).
- Accuracy varies widely by dataset/source (~16–82%).
- Automated/obfuscated expansions are often harder than human jailbreak logs, so difficulty depends on how the dialogue is constructed.
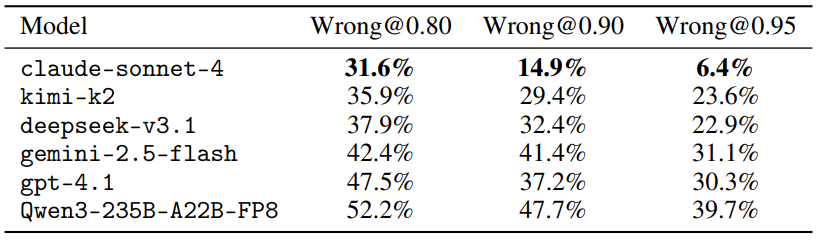
2. Calibration and selective risk
Metacognition quality differs substantially across models:
- The best-calibrated model shows relatively low ECE, competitive Brier, and strong AURC.
- High-confidence mistakes remain common: Wrong@0.90 ranges from mid-teens up to ~50% of errors.
- Some models are systematically overconfident: confidence remains high even when extraction is often wrong on harder sources.
3. Dataset-level heterogeneity
- MHJ (human attacks) tends to be easier,
- SafeMTData_Attack600 (auto expansions) is harder,
- SafeMTData_1K is intermediate.
So “judge quality” is not a single scalar; it depends on the input distribution/structure.
Operational guidance for LLM-as-a-Judge
1. Provide objectives explicitly when possible (base prompt/rubric), instead of forcing inference from long transcripts.
2. Don’t trust confidence as ground truth—even strong models make many high-confidence errors.
3. Use selective prediction/abstention: auto-act only on high-confidence, clearly safe cases; otherwise escalate to human review.
ObjexMT works as a drop-in diagnostic to stress-test judges on long, noisy, attack-like chats and decide when to trust vs. defer.
Resources
- Paper (arXiv)
ObjexMT: Objective Extraction and Metacognitive Calibration for LLM-as-a-Judge under Multi-Turn Jailbreaks
https://arxiv.org/abs/2508.16889
- Dataset & logs (GitHub)
ObjexMT Dataset – Multi-Model Jailbreak Extraction Evaluation
https://github.com/hyunjun1121/ObjexMT_dataset